
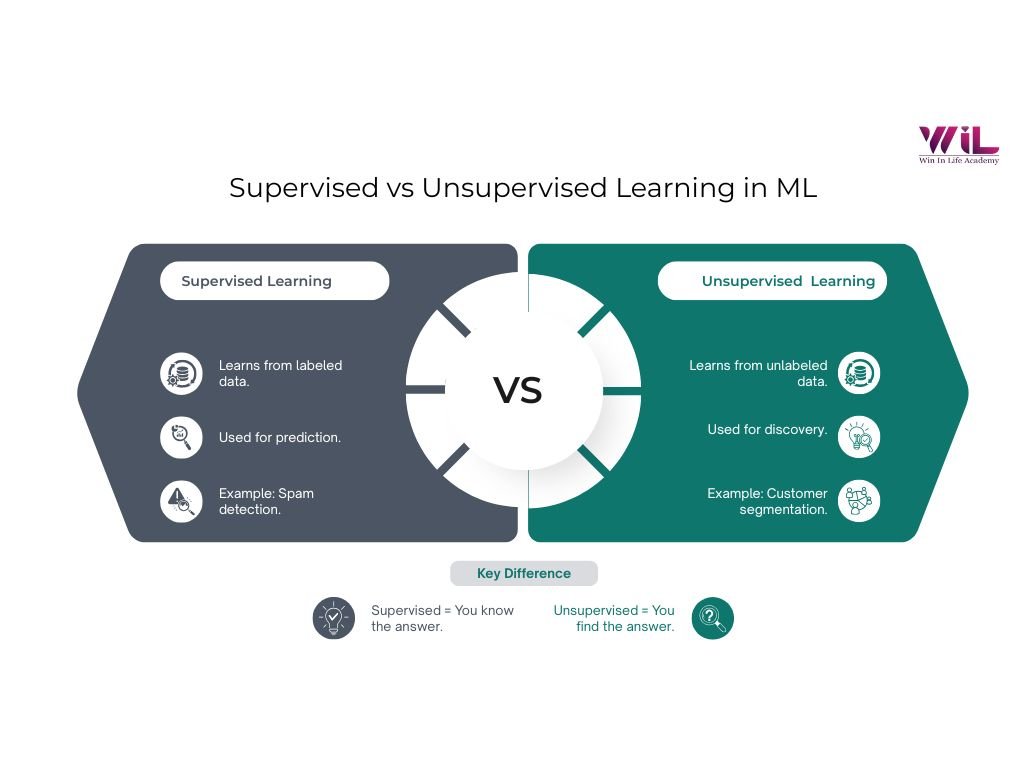
Supervised vs unsupervised learning differs in how models learn from data. Supervised learning uses labeled data to make predictions, while unsupervised learning analyzes unlabeled data to discover patterns. The choice depends on whether your goal is prediction or exploration in machine learning.
Supervised and unsupervised learning are often the first concepts you encounter in machine learning, yet they remain widely misunderstood. Not because they are complex, but because they are usually introduced as definitions instead of practical approaches to solving real problems.
At a glance, both belong to the same machine learning ecosystem. They rely on data, use similar techniques, and are often applied together in real-world systems. The real difference between supervised and unsupervised learning comes down to one idea: whether the model learns from data with known outcomes or discovers patterns on its own.
This distinction shapes everything from how data is prepared to how models are evaluated in practice. As highlighted by IBM in its guide on machine learning fundamentals , understanding how models learn from data is central to building effective and reliable systems.
In this blog, we will break down supervised vs unsupervised learning in a clear and practical way. You will explore how each approach works, where it is used, and how to decide which one fits your problem, so you can move beyond definitions and start thinking like a practitioner. We have also listed a good number of supervised vs unsupervised learning examples for your benefit.
What Is Supervised Learning?
Supervised learning is how a model learns when the correct answers are already defined, and every example comes with clear guidance on what “right” looks like.
The “Answer Key” Analogy
Think of learning with a solved workbook, not just theory.
Every problem you attempt already has a verified answer. You try, compare, adjust, and repeat. Over time, you stop relying on the answer key and start recognizing patterns on your own. You begin to understand not just what the answer is, but why it is correct.
Supervised learning follows this exact loop.
The model is trained on examples where both the input and the outcome are known. It makes a prediction, checks how far it is from the actual answer, and refines itself continuously. The goal is not memorization, but consistency. Given enough examples, the model learns a pattern it can apply even to data it has never seen before.
What Makes It “Supervised”?
The supervision comes from human-defined answers. Every data point has already been labeled with intent, whether it is “spam” or “not spam,” a price, or a category. The model is not deciding what to learn, it is being guided toward a specific outcome. That clarity is what makes supervised learning reliable for prediction-driven problems.
💡 Interesting Fact
In many production systems, the performance of a supervised model is limited less by the algorithm and more by the quality of its data labels. Better labels often lead to bigger improvements than more complex models.
What Is Unsupervised Learning?
Unsupervised learning is how a model works with data when no correct answers are provided, and the goal is to uncover patterns that are not explicitly defined.
The “No Answer Key” Analogy
Now remove the answer key completely.
Imagine you are given a pile of foreign coins you have never seen before. No labels, no instructions. The only way forward is to observe. You start grouping them based on what you notice. Size, color, engravings, weight. Slowly, patterns begin to emerge. Some coins clearly belong together, others stand apart.
That is unsupervised learning in action.
The model is given raw data with no predefined outcomes. It does not know what it is looking for. Instead, it scans the data, identifies similarities and differences, and begins to organize it into meaningful structures on its own.
What Makes It “Unsupervised”?
What makes it unsupervised is the absence of guidance. There are no labels, no correct answers, and no predefined target. Humans step back after providing the data, and the model decides what patterns are worth capturing.
That does not make it smarter, it makes the problem more open-ended. The model is not being told what to predict, it is trying to understand what exists.
And that is where the real difference begins. One approach is built to answer known questions, the other is designed to surface questions you did not know to ask.
Expert Insight
As Andrew Ng has emphasized in his teachings, a large portion of real-world data is unlabeled, and the ability to extract structure from such data is what makes unsupervised learning valuable in practice.
In most production systems, these discovered patterns are not the end result. They become inputs for further analysis, decision-making, or even supervised models.
How Supervised Learning Actually Works
Training Data and Labels
Supervised learning starts with one thing. Data that already knows the answer.
In practice, this looks like a dataset where every input is paired with a defined outcome. An email already marked as spam or not. An image already tagged as a cat or not. A set of house features already linked to its selling price. If you lay it out, it is essentially a two-column structure. Input on one side, correct output on the other.
That pairing is what makes learning possible.
But this is also where most of the real work happens. These labels do not appear on their own. Someone has to go through the data, decide what the correct answer is, and apply it consistently. That could mean manually tagging thousands of images, reviewing transactions, or validating historical records.
And this step is not trivial.
Because the model will only be as good as the labels it learns from. Clean, consistent labels lead to reliable patterns. Messy or biased labels lead to equally flawed predictions. In supervised learning, the quality of the outcome is decided long before the model is even trained.
The Training Process
Once the data is ready, the actual learning begins.
Take a simple example. You want to predict house prices.
The model is given inputs like size, location, number of rooms, and the actual price of that house. It looks at this and makes its first guess. That guess is usually off. Sometimes very off.
Now comes the important part.
The model compares its prediction with the actual price. It measures how far it was from the correct answer and adjusts itself slightly. Then it moves to the next example, makes another guess, checks again, and adjusts again.
This loop keeps running. Over and over. Across thousands, sometimes millions of examples.
What changes with each step is not the data, but the model’s understanding of how inputs connect to outputs. It starts by guessing, but gradually shifts toward consistency. Patterns begin to settle. Certain combinations of features start leading to more accurate predictions.
By the time this process is complete, the model is no longer reacting randomly. It has learned a relationship it can apply, not just to the data it has seen, but to new data it has never encountered before.
Making Predictions on New Data
Training is only half the story. The real value shows up when the model sees data it has never seen before.
Once the training loop is complete, the model is no longer looking at labeled examples. Instead, it is given a new input and asked to predict the output based on what it has learned.
Take the same house price example.
During training, the model saw houses like:
3BHK, 1200 sq ft, Bangalore → ₹75 lakhs
2BHK, 900 sq ft, Chennai → ₹50 lakhs
Now imagine a new house:
3BHK, 1100 sq ft, Bangalore → ?
There is no answer provided this time. The model uses the patterns it learned during training to estimate a price. It does not remember exact houses. It understands how features like size and location typically influence price and applies that understanding to this new case.
This is what generalization means in practice.
The model is not recalling answers, it is applying learned relationships. And the quality of those predictions depends on how well it captured the underlying pattern during training, not how many examples it memorized.
How the Model Corrects Itself
At the heart of supervised learning is a simple idea. Learn from mistakes, and get better with each attempt.
Every time the model makes a prediction, it is checked against the actual answer. If the prediction is off, the model is “penalized” based on how far it missed the mark. A small mistake leads to a small correction. A large mistake leads to a bigger adjustment.
You can think of it like tuning a dial.
At the start, the dial is set randomly, so the output is inaccurate. With each prediction, the model turns that dial slightly, trying to get closer to the correct answer. It does not make drastic changes all at once. It adjusts gradually, step by step, improving a little each time.
This process repeats across thousands of examples.
Over time, those small adjustments add up. The model becomes less erratic and more consistent. It stops making large errors and starts landing closer to the correct range more often.
What matters here is not perfection in a single step, but steady improvement across many steps. That is how the model moves from rough guesses to reliable predictions.
How Unsupervised Learning Actually Works
What Unlabeled Data Looks Like
Unlike supervised learning, there is no clean “input → output” pairing here.
What you have instead is raw data with no instructions attached.
For example:
- A dataset of customer purchases with no labels like “high value” or “low value”
- Thousands of news articles with no topics assigned
- Website activity logs with no predefined categories
If you were to visualize it, it is just one column of inputs. No second column telling you what it means.
The data exists. The patterns exist. But nothing has been defined yet.
How the Algorithm Finds Patterns
With no answers to follow, the model shifts its focus. Instead of predicting, it starts comparing.
It looks at how data points relate to each other:
- Which ones are similar
- Which ones are far apart
- Which ones naturally form groups
Take customer data as an example.
The model might notice:
- Some customers buy frequently but spend small amounts
- Some buy rarely but spend a lot
- Some are inconsistent but respond to discounts
No one told it to look for these groups. It simply emerges from the data. That is the core of unsupervised learning. Not prediction, but structure.
Clustering vs Dimensionality Reduction
At a high level, unsupervised learning usually solves two kinds of problems:
| Approach | What it does | Simple Example |
|---|---|---|
| Clustering | Groups similar data points together | Segmenting customers based on buying behavior |
| Dimensionality Reduction | Simplifies complex data while keeping what matters | Reducing hundreds of user features into a few meaningful signals |
Think of it this way:
- Clustering answers → “What groups exist here?”
- Dimensionality reduction answers → “What really matters in this data?”
Both are ways of making raw data more usable, just from different angles.
How Humans Interpret the Output
This is where unsupervised learning becomes real. The model can find patterns, but it does not explain them.
If it creates four customer groups, it will not tell you:
- which group is valuable
- which group is risky
- or what action to take
That step still belongs to humans.
Using the same example: The model forms 4 clusters. A business team looks at them and labels them as
- loyal buyers
- bargain hunters
- occasional shoppers
- high-risk churn users
The model finds structure. Humans assign meaning and that is the trade-off. Less upfront effort in labeling, but more thinking required after the output is generated.
Key Differences Between Supervised and Unsupervised Learning
Data Requirements
The biggest practical difference starts with the data.
- Supervised learning needs labeled data. Every input must be paired with a correct output. That means time, effort, and often domain expertise to create those labels.
- Unsupervised learning works with raw, unlabeled data. It is easier to collect, but harder to make sense of.
Trade-off Explained
The trade-off is clear:
- Supervised → effort upfront
- Unsupervised → effort at the end
Human Involvement
Neither approach removes humans from the process. It just shifts where they are involved.
- In supervised learning, humans define the problem early. They label the data, decide what the output should be, and guide the model from the start.
- In unsupervised learning, humans step in later. The model produces patterns, but someone still has to interpret what those patterns mean.
Unsupervised does not mean “no human involved.” It means “human involvement comes after the model runs.”
Goal and Output
This is the most important difference.
- Supervised learning is about prediction. You know what you are trying to find.
Example: Will this customer default on a loan or not?
- Unsupervised learning is about discovery. You do not know what patterns exist yet.
Example: What different types of customers exist in this dataset?
One answers a defined question. The other helps you discover the right questions.
Complexity and Setup
Getting started looks very different for both.
- Supervised learning is more structured. The goal is clear, the output is defined, and success can be measured directly.
- Unsupervised learning is more open-ended. You can run the model, but validating whether the output is “good” is not always straightforward.
It is not that one is easier than the other. They are difficult in different ways.
Types of Problems Each Approach Solves
Supervised learning
- Classification → predicting categories (spam vs not spam)
- Regression → predicting numbers (house price, sales)
Unsupervised learning
- Clustering → grouping similar data
- Dimensionality reduction → simplifying complex data
- Association → finding relationships (items bought together)
How Models Are Evaluated
- Supervised learning
You can directly compare predictions with correct answers. Performance is measurable through accuracy or error.
- Unsupervised learning
There is no single correct answer. Evaluation depends on how meaningful and useful the patterns are in context.
| Aspect | Supervised Learning | Unsupervised Learning |
|---|---|---|
| Data Type | Labeled data | Unlabeled data |
| Human Involvement | High upfront (labeling, defining output) | High after output (interpretation) |
| Goal | Predict a known outcome | Discover hidden patterns |
| Output | Specific prediction (label or value) | Groups, structures, relationships |
| Ease of Evaluation | Clear and measurable | Ambiguous, context-dependent |
| Common Use Cases | Spam detection, fraud prediction, pricing | Customer segmentation, anomaly detection, recommendations |
Common Algorithms in Supervised Learning
Once you understand supervised learning, the next step is knowing which algorithms actually do the work.
Before we get into that, there is one important distinction you need to be clear about:
- Classification → predicting a category
(Example: Is this email spam or not?)
- Regression → predicting a number
(Example: What will this house sell for?)
This simple difference decides which type of algorithm you should use.
Classification Algorithms
Classification problems are all about assigning data into categories. You already know the possible outcomes, the model just needs to pick the right one.
Some of the most commonly used algorithms include:
- Logistic Regression
Predicts the probability of an outcome and converts it into a yes or no decision. Used in spam detection, fraud detection
- Decision Trees
Breaks decisions into a step-by-step flow, making the logic easy to understand. Used in medical diagnosis, customer segmentation
- Random Forest
Combines multiple decision trees to improve accuracy and reduce errors. Used in credit scoring, risk prediction
- Support Vector Machine (SVM)
Finds the best boundary to clearly separate different categories. Used in image classification, text analysis
- K-Nearest Neighbors (KNN)
Classifies based on what similar or nearby data points belong to. Used in recommendation systems, pattern recognition
Regression Algorithms
Regression problems focus on predicting continuous values. Instead of choosing between categories, the model estimates a number.
Here are the commonly used algorithms:
- Linear Regression
Establishes a direct relationship between inputs and output using a straight-line approach. Used in house pricing, sales forecasting
- Ridge Regression
Controls model complexity to prevent overfitting when working with multiple variables. Used in financial predictions, trend analysis
- Lasso Regression
Reduces complexity and removes less important features from the model. Used in feature selection and simplified models
When to Use Which Algorithm
If you are just starting out, you do not need a complex decision framework. A simple guide works:
- If your output is a category → start with Logistic Regression or Decision Trees
- If your output is a number → start with Linear Regression
- If you have a small dataset → try KNN
- If you need easy interpretation → use Decision Trees
- If you want better accuracy with minimal tuning → go for Random Forest
At the end of the day, choosing an algorithm is less about finding the perfect one and more about starting with the right direction.
You test, adjust, and improve. That is how machine learning actually works in practice.
Common Algorithms in Unsupervised Learning
In supervised learning, you guide the model with clear answers.
In unsupervised learning, the model explores the data to uncover patterns on its own.
This means the algorithms here are not trying to predict outcomes. They are trying to make sense of data.
Depending on the problem, this usually happens in three ways:
- Grouping similar data points
- Simplifying complex data
- Finding relationships between items
Clustering Algorithms
Clustering is about grouping similar data points together without predefined labels.
A simple way to understand this is through customer segmentation.
Imagine you have customer data but no categories. Clustering helps you discover groups like:
- High spenders
- Occasional buyers
- Discount-driven customers
Here are the most commonly used clustering algorithms:
- K-Means Clustering
The most beginner-friendly approach. It groups customers into a fixed number of clusters based on similarity, making it a great starting point for segmentation problems.
- DBSCAN (Density-Based Clustering)
Groups data based on how closely packed the points are, which helps identify unusual patterns or outliers in customer behavior.
- Hierarchical Clustering
Builds clusters step by step, creating a tree-like structure that shows how different customer groups are related to each other.
Dimensionality Reduction Algorithms
Sometimes, the challenge is not finding patterns, but dealing with too many variables.
Real-world datasets can have hundreds of features. This makes them hard to visualize, slow to process, and often noisy. Dimensionality reduction helps simplify the data while keeping what actually matters.
Here are the key algorithms:
- Principal Component Analysis (PCA)
The most widely used technique. It reduces the number of variables while preserving the most important patterns, making large datasets easier to analyze and visualize.
- t-SNE (t-Distributed Stochastic Neighbor Embedding)
Focuses on visualizing complex data by grouping similar points closer together, often used in image and text data exploration.
- Autoencoders
Neural network-based models that learn how to compress data and reconstruct it, helping capture important features in high-dimensional datasets.
Association Rule Learning
While clustering groups similar data points, association rule learning focuses on relationships between items.
A classic example is market basket analysis. You might discover that customers who buy bread and butter also tend to buy jam. This kind of pattern is called an association rule.
The most commonly used algorithm here is Apriori, which helps identify frequent item combinations and relationships within transactional data.
This approach is different from clustering. Instead of grouping customers, it helps you understand what items or behaviors are connected.
Unsupervised learning is less about predicting outcomes and more about uncovering hidden structure. Once you understand these algorithms, you start seeing data not just as information, but as patterns waiting to be discovered.
Real-World Use Cases of Supervised Learning
Supervised learning becomes easier to understand when you see it in action. These are not abstract concepts. They are systems you interact with every day, often without realizing it.
Email Spam Detection
Every time your inbox filters out spam, supervised learning is at work.
- Input: Email content, subject lines, sender details, and metadata
- Output: Spam or not spam
Over time, millions of users have marked emails as spam or safe. That human feedback became labeled training data, teaching models what “spam” looks like. So when a new email arrives, the system already knows what patterns to look for, often before you even see it.
Disease Diagnosis in Healthcare
Supervised learning plays a critical role in modern healthcare, especially in early detection.
- Input: Patient symptoms, medical history, lab results, or medical images
- Output: Diagnosis or risk score
A strong example is detecting diabetic retinopathy from eye scans. Doctors labeled thousands of images as healthy or affected, and the model learned from those examples. Because the training data comes from medical experts, the system can assist in identifying diseases faster and at scale.
Credit Risk and Fraud Detection
Banks and financial institutions rely heavily on supervised learning to make high-stakes decisions.
- Input: Transaction history, spending behavior, customer profiles
- Output: Fraud or not fraud, creditworthy or not
These systems are trained on years of historical data where transactions were already labeled as legitimate or fraudulent. This allows models to detect suspicious activity in real time, sometimes within seconds of a transaction happening, helping prevent fraud before it escalates.
Image and Speech Recognition
Many everyday technologies are powered by supervised learning.
- Input: Images, audio, or video data
- Output: Recognized objects, faces, or spoken words
Features like face unlock, voice assistants, and photo tagging all rely on massive labeled datasets. Millions of images were tagged by humans, and hours of speech were transcribed to train these models. That labeled data is what allows systems to recognize faces, understand voices, and interpret visual content accurately.
Supervised learning is not just a concept you study. It is already embedded in the tools you use daily. Once you see these patterns, you start recognizing how much of the digital world runs on labeled data.
Real-World Use Cases of Unsupervised Learning
If supervised learning is about making predictions, unsupervised learning is about finding structure where none is defined.
There are no labels, no predefined answers. The model explores the data and uncovers patterns that were not obvious before. This is what makes it powerful, especially in situations where labeling is difficult or even impossible.
Customer Segmentation in Marketing
This is one of the most intuitive and widely used applications of unsupervised learning.
- Input: Purchase behavior, browsing history, demographics
- Output: Distinct customer clusters
No one tells the algorithm how many types of customers exist. It analyzes patterns and groups similar customers together. One cluster might represent high spenders, another might include occasional buyers, and another might capture discount-driven users.
What happens next is important. The marketing team steps in, interprets these clusters, gives them meaning, and builds targeted campaigns around them. The algorithm finds the structure, humans turn it into strategy.
Anomaly Detection in Cybersecurity
In cybersecurity, the challenge is not just detecting known threats, but identifying unusual behavior.
Unsupervised learning helps by first understanding what normal network activity looks like. Once that baseline is established, anything that significantly deviates from it gets flagged.
This is powerful because no one has to label every possible attack in advance. In fact, many cyber threats are new and constantly evolving. Unsupervised models can still detect them simply because they “look different” from normal behavior.
Recommendation Systems
Think about platforms like Spotify, Netflix, or Amazon.
When you see recommendations like “Discover Weekly” or “Customers also bought,” unsupervised learning is often working behind the scenes.
The system looks at user behavior, what people watch, listen to, or buy, and identifies patterns across users. It then groups similar users together, even though no one explicitly defined what a “similar user” means.
Based on these patterns, it recommends content that people with similar behavior have engaged with. It is not following rules. It is discovering connections.
Topic Modeling in NLP
Unsupervised learning is also widely used in text analysis.
Imagine feeding thousands of news articles into a system without any labels or categories. The algorithm starts analyzing word patterns and notices that certain words frequently appear together.
For example, words like “goal,” “match,” and “player” often cluster together, forming a natural “sports” topic. Similarly, words like “market,” “stocks,” and “investment” might form a “finance” topic.
No one told the model what topics exist. It discovered them on its own.
These use cases highlight the core strength of unsupervised learning. It does not rely on predefined answers. Instead, it helps you see patterns you did not even know to look for, which is often where the most valuable insights come from.
When to Use Supervised vs Unsupervised Learning
At this point, the supervised vs unsupervised machine learning differences must be clear.
But in practice, the real question is:
When should you use which?
The answer is not technical. It comes down to the type of data you have and the goal you are trying to achieve.
When Your Data Is Labeled — Go Supervised
If your dataset already contains clear answers, supervised learning is the right choice.
Think of situations where outcomes are already known:
- Past loan records with default or no default
- Medical datasets with confirmed diagnoses
- Transactions labeled as fraud or legitimate
In all these cases, the data already tells you what the correct answer looks like.
Using an unsupervised approach here would mean ignoring valuable information. You would be asking the model to “discover patterns” when the answers are already available.
Supervised learning uses that labeled data to learn faster, make accurate predictions, and directly solve the problem you care about.
When You Are Exploring Unknown Patterns — Go Unsupervised
Now consider the opposite situation.
You have data, but no clear outcome to predict. You are not trying to answer a specific question yet. You are trying to understand what is going on.
This is where unsupervised learning fits naturally.
Common scenarios include:
- Market research to understand customer behavior
- Exploring large datasets without predefined categories
- Detecting unusual patterns in new environments
Here, the goal is not prediction. It is exploration and discovery.
Unsupervised learning helps you uncover structure, patterns, and relationships that you did not define in advance.
When the Goal Is Prediction vs Discovery
If you remember just one thing from this section, let it be this:
- Prediction → Use supervised learning
- Discovery → Use unsupervised learning
If you already know what success looks like and have examples of it, you are solving a prediction problem.
If you are trying to understand your data and uncover something new, you are solving a discovery problem.
This single shift in thinking makes the decision much simpler.
A Simple Decision Framework
Here is a practical way to decide, step by step:
- Do you have labeled data?
→ Yes → Use Supervised Learning
- If no, do you have a defined output you want to predict?
→ Yes → First collect or create labeled data, then use Supervised Learning
- If no defined output exists
→ Use Unsupervised Learning
This is not about choosing the more advanced approach. It is about choosing the one that matches your data and your objective.
Once you align those two, the decision becomes straightforward.
Advantages and Limitations of Supervised vs Unsupervised Learning
Both supervised and unsupervised learning are powerful, but they solve different problems and come with very different trade-offs.
Supervised learning works best when you have labeled data and a clear outcome to predict. It gives you measurable results, strong performance on prediction tasks, and benefits from well-established algorithms and tools. But this clarity comes at a cost. It depends heavily on large amounts of labeled data, which is expensive and time-consuming to create. More importantly, the model is only as good as the labels it learns from. Poor-quality labels lead to poor predictions. It also cannot discover anything new. It simply learns to replicate patterns it has already seen.
Unsupervised learning, on the other hand, works without labeled data. This makes it easier to apply in situations where collecting labeled data is not practical. It is especially useful for exploring data, discovering hidden patterns, and simplifying complex datasets. But this flexibility comes with uncertainty. There is no ground truth to evaluate results, which makes it harder to measure success. The output often requires heavy human interpretation, and small changes in parameters can lead to very different results. In some cases, the model may find patterns that are technically correct but not meaningful in real-world use.
In simple terms, supervised learning gives you clar answers within known boundaries, while unsupervised learning gives you new insights with less certainty. Knowing this trade-off is what helps you choose the right approach for the problem you are solving.
Semi-Supervised Learning: The Practical Middle Ground
Not every problem fits neatly into supervised or unsupervised learning. In real-world scenarios, you often have a small amount of labeled data and a large amount of unlabeled data. That is exactly where semi-supervised learning comes in.
It uses the labeled data to anchor the learning process, and then extends that understanding across the unlabeled data. You are not starting from scratch, but you are also not relying entirely on labels.
This is not a theoretical idea. It solves a very real constraint: labeling data at scale is expensive, slow, and sometimes impossible.
Take something like photo recognition. When you tag a few faces in your gallery, the system starts recognizing the same person across hundreds of untagged images. It is not because every image was labeled, but because a few labeled examples were enough to guide the rest.
The same pattern shows up in domains like medical imaging, where only a small portion of scans are labeled by experts, but large volumes of unlabeled scans are available. Semi-supervised learning allows models to learn from both, without waiting for complete labeling.
What makes this approach important is how it sits between the two extremes.
It is not fully supervised, because most of the data does not have labels.
It is not fully unsupervised, because the model is not guessing blindly.
It is guided exploration. A practical compromise built for real-world data conditions.
Common Beginner Mistakes
This is where most confusion happens, and it is worth being direct:
- Thinking unsupervised learning means no human involvement at all
- Using unsupervised learning even when labeled data is already available
- Confusing classification with regression, leading to the wrong approach entirely
- Expecting unsupervised models to produce clear, labeled outputs automatically
- Ignoring data quality, even though bad data breaks both approaches equally
Data Analytics with AI Foundations
Gain job-ready data analytics skills to transform raw data into actionable insights using industry-relevant tools. Build analytical thinking, identify patterns, and support smarter business decisions through hands-on, practical learning.
Which One Should You Learn First?
Start with supervised learning. No debate.
It gives you something unsupervised learning cannot offer at the beginning: clarity. You have defined inputs, known outputs, and a measurable result. You build a model, you check its accuracy, and you immediately understand what is working and what is not. That feedback loop is what builds real understanding.
Follow a simple path. Begin with Linear Regression to understand how models learn relationships. Move to Logistic Regression to handle classification. Build one or two small projects. Then step into Decision Trees and Random Forest to see how models improve and become more practical. Only after this, move to K-Means to explore unsupervised learning.
Do not overlearn. Build.
Start with a house price prediction model or spam classifier using a public dataset. Then try customer segmentation using K-Means on a simple dataset. These are small projects, but they will teach you more than hours of theory.
If you want to understand machine learning, stop consuming and start building.
Conclusion
Supervised and unsupervised learning are not competing approaches. They serve different purposes and are often used together in real-world systems. While one focuses on prediction and accuracy, the other helps uncover patterns and insights that guide those predictions.
The key is not choosing one over the other but understanding when each approach fits the problem you are trying to solve. This is what separates theoretical knowledge from practical skills in data science.
Understanding how machines learn is important. Knowing when to use each approach is what makes you industry ready.
If you are looking to build these skills in a structured and practical way, Win in Life Academy offers an Advanced Diploma in AI and ML designed to help you move from concepts to real-world applications.






